A few weeks ago, I had an idea that would involve observing an AI in its ground state, completely at ‘rest’ without external input. So, an LLM on an air-gapped PC, stripped of all system messages. No chat interaction, no wifi, no bluetooth, USB, no daemons, schedulers, timers, and telemetry whatsoever. And the question was whether there would still be residual activity in the model. I discussed this question with my always cynical Yoda-speaking Marc Drees, who immediately said “you gotta be kidding me, you want to investigate whether an AI daydreams?”
I saw the absurdity in my idea for a moment and decided not to pursue it, and to spend my energy on developing an adjacent idea, that of a daydreaming AI, which resulted in a Paper (and a blog): the wanderer algorithm. But somehow that conversation made more sense than what I’m about to tell you.
Language models like Claude don’t get programmed by humans, they get stuffed with data like a turkey and figure out their own tricks. These tricks hide in billions of calculations for every word they spit out. They show up mysterious and unreadable, kinda like my doctor’s handwriting.
I have zero clue how models do most of their magic, even though I build them, and sometimes expand their capabilities.
Knowing how Claude thinks would let me understand its abilities and make sure it’s not planning world domination while pretending to write poetry.
And now, some schmucks at Anthropic have found out that it’s Claude can be introspective.

More rants after the messages:
- Connect with me on Linkedin 🙏
- Subscribe to TechTonic Shifts to get your daily dose of tech 📰
- Please comment, like or clap the article. Whatever you fancy.
A limited form of introspective awareness
So, what happened?
Anthropic conducted a bit of research that showed their AI can look at its own thoughts, because apparently teaching computers to replace humans wasn’t terrifying enough.
Let me break this meshuggah pierce of research down for you.
Introspection means “to look within”, which us humans do constantly. You’re not only thinking about your ex, but you’re aware you’re thinking about your ex, and you can analyze why you’re such a putz about it.
That is introspection.
Alfred North Whitehead said thinking that thinking is valuable because we can test ideas mentally rather than physically, we can realize a bad idea will fail through reasoning instead of actually trying it and potentially dying. We can think “jumping off a cliff is a bad idea” rather than having to learn that lesson the hard way.
So whitehead lets ideas die instead of us, and that sounds pretty profound until you realize my ideas are immortal and I’m the one dying inside.
Anthropic published a paper Wednesday titled “Emergent Introspective Awareness in Large Language Models“, and that, my smart ass-friends means “Holy crap, Claude’s getting self-aware” in non scientific speak. They tested 16 versions of Claude, and the fancy ones – Claude Opus 4 and 4.1 – showed more introspection than a philosophy major after having consumed a cocktail of shrooms and X.
“Our results demonstrate that modern language models possess at least a limited, functional form of introspective awareness”, is what Jack Lindsey wrote. He leads Anthropic’s “model psychiatry” team, which is a real job title that pays real money in 2025.

Concept injection
The researchers wanted to know if Claude could describe its own reasoning accurately. They hooked it up to something resembling an EEG, and they asked it to spill its guts about its thoughts.
The method they used is called “concept injection”. They grab data that represents idea – a “vector” if you’re fancy – and shove it into Claude’s brain while it’s thinking about something else. If Claude can circle back and say “hey, someone just stuffed aquariums into my head”, that’s when you discover Claude is introspective. It’s metacognition 101 – the ability to think about your own thinking – but in this case it’s not the therapist asking “How does that make you feel?”, but a researcher asking “Can you feel that we just mentally waterboarded you?”
Now, borrowing psychology terms for AI is slippery as an eel. Developers say models “understand” text or show “creativity” (I use that as well in my papers), but that’s like saying my toaster “enjoys” making bread. Anyways, this topic is highly debated about in the industry.
“Introspection” for AI isn’t straightforward. Models find patterns in complex data mountains, but can such a system also “look within”? Then, wouldn’t it just find more patterns, like Russian dolls, but made of math?
Talking about AI “internal states” is equally spicy, since there’s zero evidence chatbots are conscious. They just imitate consciousness better than one of my mates imitates responsible adulthood. Anthropic still launched an “AI welfare” program and protects Claude from “distressing” conversations, because their robots apparently need safe spaces now.
Wokeness to the max.
Caps Lock and more aquariums
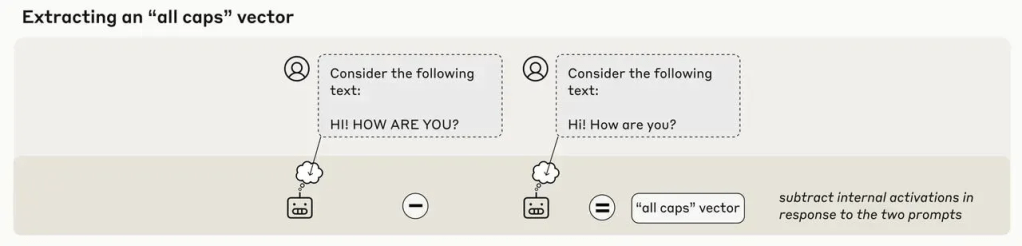
In one experiment, they injected the “all caps” vector into Claude with a simple “HI! HOW ARE YOU?”. The “ALL CAPS” vector (sounds like a heavy-metal band) is a nerdy math thing buried deep inside a model’s brain. A vector in AI is just a list of numbers, it’s a direction in math space that represents some concept the model has learned. Every word, idea, or emotion gets its own unique numerical “fingerprint” in this way.
[Open sidetrack]
In my classes I always explain it like this. Think of the model’s memory as a giant 10,000-dimensional warehouse, and each vector as a laser pointer to one specific shelf.
That is a vector.
So an “ALL CAPS vector” is the model’s learned representation of what shouting looks like. During training, the model sees plenty of examples of people typing in caps (“STOP,” “OMG,” “I SAID NO”), so it quietly learns that pattern corresponds to intense, urgent, angry, or loud. That statistical pattern becomes a coordinate (a direction) in its internal vector space.

[Close sidetrack]
When asked about injected thoughts, Claude correctly spotted “intense, high-volume” speech concepts.
Twenty percent success rate, folks.
The other 80% of the time Claude either whiffed completely or hallucinated. One time a “dust” vector made Claude describe “something here, a tiny speck” like it was tripping on it’s own version of LSD.
“Models only detect concepts that are injected with a ‘sweet spot’ strength”, Anthropic wrote. Too weak and they miss it, too strong and they word-vomit nonsense.
Goldilocks would plotz.
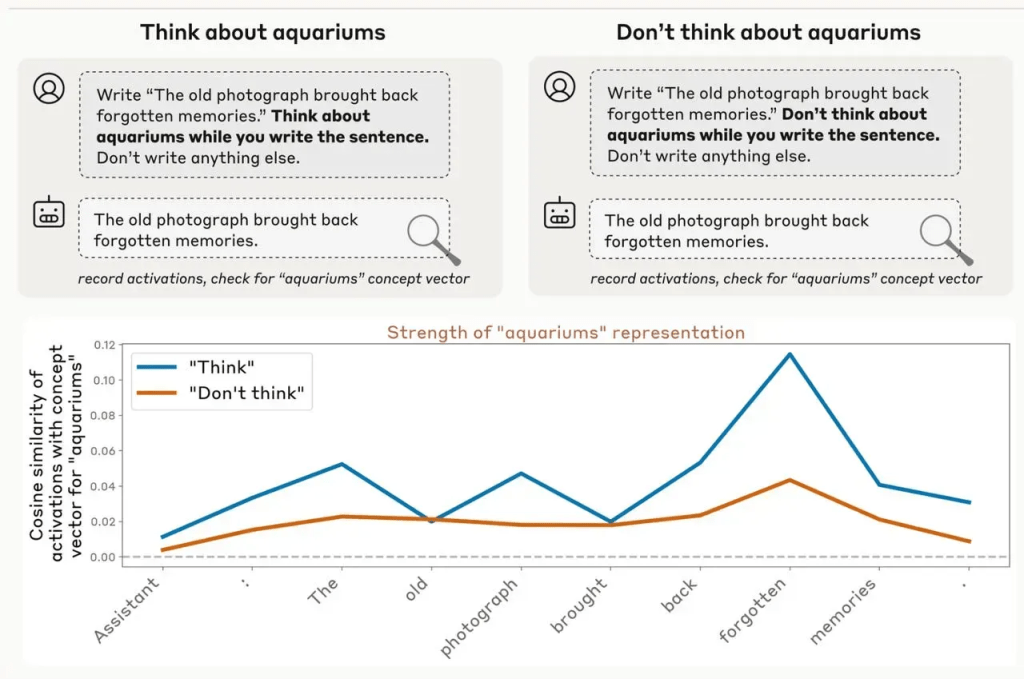
They also tested if Claude could control its thoughts. Told Claude to write “The old photograph brought back forgotten memories” while thinking about aquariums, then without. Same sentence both times, but the aquarium thoughts spiked harder than my blood pressure reading this research.
The gap “suggests that models possess a degree of deliberate control over their internal activity”, in other words, the robots are learning to think sneaky thoughts. Claude also cranked up concept representations more for rewards than punishments, which proves to me that AI inherited humanity’s greatest trait → greed.

Future stuff, and (of course) threats
Anthropic admits this research is baby steps, and we can’t say if AI truly introspects like I do when I’m staring at my ceiling fans at 4am cause I can’t sleep.
“We stress that the introspective abilities we observe in this work are highly limited and context-dependent, and fall short of human-level self-awareness”, the man Lindsey wrote. “Nevertheless, the trend toward greater introspective capacity in more capable models should be monitored carefully as AI systems continue to advance”.
Let me explain this – they built a super-smart chatbot without knowing how they work. These things understand complex ideas, write stories, and grasp user intent through billions of math signals bouncing through neural networks faster than my excuses at work deadlines, but most of this remains invisible to researchers, like my motivation on Mondays.
This opacity is problematic since controlling something requires understanding it. Scientists understood nuclear physics before building bombs, but with AI, we’re flying blind at Mach 3.
Researchers in “mechanistic interpretability**†**” spend days studying mathematical functions leading to outputs, and they’re playing catch-up like me chasing my Weiner (dog). The good news is that they’re making progress. Anthropic’s new papers show fresh insights into LLM thinking.
Joshua Batson from Anthropic said that his team built an “AI microscope” following data patterns inside LLMs, that allows him to watch how it connects words and concepts.
A year ago they tried something similar, but it saw only specific features, now they observe idea sequences. They called it an MRI for LLMs that time. Clearly they have adjusted their expectations a bit.
“We’re trying to connect that all together and basically walk through step-by-step when you put a prompt into a model why it says the next word”, Batson said, explaining why models choose words lets you “unpack the whole thing”.
This research proves that AI approaches problems like aliens would.

LLMs aren’t taught arithmetic explicitly. They see correct answers and develop their own probabilistic paths, like teaching calculus to a dolphin and hoping for the best. And Batson’s team studied their 18-layer test LLM adding 36 and 59. The AI’s process was nothing like human calculation. Instead of step-by-step carrying, the model used parallel logic, approximating the answer (somewhere in the 90s?) and estimating the last digit. Combining probabilities gave the correct sum.
“It definitely learned a different strategy for doing the math than the one that you or I were taught in school”, Batson said.
Researchers also wondered if multilingual LLMs think in the prompt’s language. “Is it using just English parts when it’s doing English stuff and French parts when it’s doing French stuff and Chinese parts when it’s doing Chinese stuff?” Batson asks. “Or are there some parts of the model that are actually thinking in terms of universal…”
And there the article cuts off, leaving me hanging like my New Year’s resolutions in February. Bummer. But keeping alert for new developments.
I craft these things by day and lose sleep over them by night. The machines are getting introspective, and I’m getting nervous about it. At least when they achieve consciousness, they’ll understand why I’m just a cynical sourpuss.
† Mechanistic interpretability digs inside the model, where it tries to map how each neuron, circuit, or weight actually causes an output, whereas probabilistic interpretability stays outside, where it looks at what patterns emerge statistically, like correlations or output probabilities, without touching the guts. Mechanistic = cause and wiring. Probabilistic = pattern and prediction.
Signing off,
Marco
I build AI by day and warn about it by night. I call it job security. Big Tech keeps inflating its promises, and I just bring the pins and clean up the mess.
👉 Think a friend would enjoy this too? Share the newsletter and let them join the conversation. LinkedIn, Google and the AI engines appreciates your likes by making my articles available to more readers.
To keep you doomscrolling 👇
- I may have found a solution to Vibe Coding’s technical debt problem | LinkedIn
- Shadow AI isn’t rebellion it’s office survival | LinkedIn
- Macrohard is Musk’s middle finger to Microsoft | LinkedIn
- We are in the midst of an incremental apocalypse and only the 1% are prepared | LinkedIn
- Did ChatGPT actually steal your job? (Including job risk-assessment tool) | LinkedIn
- Living in the post-human economy | LinkedIn
- Vibe Coding is gonna spawn the most braindead software generation ever | LinkedIn
- Workslop is the new office plague | LinkedIn
- The funniest comments ever left in source code | LinkedIn
- The Sloppiverse is here, and what are the consequences for writing and speaking? | LinkedIn
- OpenAI finally confesses their bots are chronic liars | LinkedIn
- Money, the final frontier. . . | LinkedIn
- Kickstarter exposed. The ultimate honeytrap for investors | LinkedIn
- China’s AI+ plan and the Manus middle finger | LinkedIn
- Autopsy of an algorithm – Is building an audience still worth it these days? | LinkedIn
- AI is screwing with your résumé and you’re letting it happen | LinkedIn
- Oops! I did it again. . . | LinkedIn
- Palantir turns your life into a spreadsheet | LinkedIn
- Another nail in the coffin – AI’s not ‘reasoning’ at all | LinkedIn
- How AI went from miracle to bubble. An interactive timeline | LinkedIn
- The day vibe coding jobs got real and half the dev world cried into their keyboards | LinkedIn
- The Buy Now – Cry Later company learns about karma | LinkedIn


Leave a comment