So yeah… it’s been a while since that “State of AI in Business 2025” report was let loose on the “unsuspecting” AI community back in July, courtesy of a bunch of MIT folks who apparently had too much time or too little caffeine, so they went out interviewing execs to see if GenAI was actually paying any rent.
Their answer was unequivocally n-n-n-n-NOPE (read like Elmer Fudd).
According to our friends from the land of acronyms and grant money, 95% are still snoring in the cost column and only a brave 5% manage to crawl toward something that vaguely resembles ROI on the CAPEX side.
And that, my dear above-intelligent reader, was the moment that Generative AI got its media death warrant in triplicate. It got stabbed in the back by its own hype, and true to the ritual of the investor court, Agentic AI was anointed the new monarch by Big Tech’s royal PR clergy.

Now, you might wonder why I didn’t do a write-up when the hype exploded immediately after it happened?
Well the answer is not so simple.
MIT doesn’t exactly shy away from the spotlight.
In case you missed the memo, publicity equals funding, prestige, and tenure extensions in academia. It is literally publish or perish, baby. And when the pressure hits boiling point, the ecosystem starts breeding a special kind of parasite named predatory publishing.
I get approached by email sent by journals that look legit at first glance with sleek logos, fake impact factors, a “peer review” process that only lasts 24 hours without having to beg. It is too good to be true. And it is all designed to siphon money from desperate researchers who just need one more paper to keep their contracts alive. Yes, it is akin to an addiction. It’s a multibillion-dollar grift built on the desperation economy of academia.
You pay to publish, they pocket the coin, and everyone pretends it is knowledge. The result is that there are thousands of PDFs full of zero substance.
I call it zombie research.
And it’s not the shady back-alley journals alone because even the top-tier outfits have learned the game. They dangle “open access” fees, and “fast-track” options, and PR tie-ins, because, hey, why let the fakes have all the fun and cash, huh!?
And that’s why I stay independent.
I fund my own damn research time. I make my living deflating the bubble, and actually building the stuff these guys just talk about. I experiment, test, break, rebuild, and then write about what actually works. Because when you’re chasing citations instead of solutions, you are doing nothing but useless performance art, but with footnotes.
And yeah… I am not accusing MIT of spreading fake news, but I think these guys kinda hit “Publish” a little too early.
And in this piece amma tell you why I think this is the case.
Let’s fillet this monster now, shall we?

More rants after the messages:
- Connect with me on Linkedin 🙏
- Subscribe to TechTonic Shifts to get your daily dose of tech 📰
- Please comment or like the article, that will put TTS on the map !
Dawn of the Dead
It was Friday morning, I woke up, turned on the light, and the first thing I always do is switch on Flipboard (an interactive magazine) to see what news I have missed from the night before, because you never know. . . And that particular night before, MIT NANDA† launched “The GenAI Divide: State of AI in Business 2025”. It took me a full hour of professional procrastination (scrolling) before I remembered I was supposed to be vertical. And then I spent 15 minutes under the shower wondering if I should update my LinkedIn to “Professional Disappointment Consultant” and call it a day.
I think that this MIT study has gotten every GDPR and risk committee around the world popping champagne like it’s the Y2K all over again, because in it, they stated that 95% of enterprise AI projects are basically a failure, and that only 5% has hope it will generate some returns and there’s in total 40B US coin down the drain.
Not value. No, 40B pure cold, hard coin.
Well now, when I saw that number, my brain went, “Oh, so low, just forty?” As in, forty billion? The total AI investment up to 2024 already breaks 100 billion, and the first half of 2025 alone adds roughly another 95. Simple math, though clearly, NANDA didn’t (this was NANDA who created the report, not CSAIL‡, remember that distinction, folks).
My second thought was that we have become so desensitized to billions flying around like it’s nothing that forty almost sounds quaint. The EU announces €200B digital packages, Big Tech burns through another fifty R&D foreplay (and sacking thousands at the same time), and everyone claps like we’re saving the species instead of inflating the bubble.
And somewhere along the way, the zeroes stopped meaning anything to me.
So after realizing this, I told myself I’d spend a bit of time slashing through the report to see what kind of logic was stitched together inside. You know, the usual morning autopsy before coffee. If there was any substance behind the headlines, I’d give it credit. But if it was another glossy PDF who sells itself as research, I was ready to carve it open and look at it’s entrails.
And I gotta tell you, it leaked data, bias, and it has a desperate need for attention.
So I reached for the scalpel.
† Doesn’t that sound like a yoga pose your therapist would recommend? – ‡ MIT CSAIL, Computer Science and Artificial Intelligence Laboratory → The big one. Core research in machine learning, robotics, NLP, mathematics of computation, etc.
The study that studied . . . Nothing
MIT’s crack‡ research team interviewed a whopping 52 people, surveyed 153 conference attendees (I kid you not), and cherry-picked 300 “public AI initiatives” to conclude that the entire global AI enterprise is basically one giant ₣☋₵₭-up.
And when you have a college degree, you prolly finished your “Quantitative Research Methods 101” (not required for gender studies), back in your freshman year, and then you know this type of sampling is more like polling thirteen people at a Starbucks and declaring that coffee drinkers are not morning persons (biologically, spiritually and morally).
And then there was a guy with a name that sounds like he loves to play tennis, “Chris Dunlop”, who happens to make his living as some AI dude from New Zealand, and who also apparently does AI for the All Blacks and their stock exchange. Well, he took one look at this methodology and he called it “utter nonsense” and probably did a haka right after this feat.
The man’s got a point though.
If you’ve worked with enterprises for 3.4 seconds, you know two things, one → they keep their mouths shut about everything, and two → if they find a competitive advantage, they will guard it like a dragon hoarding gold.
But MIT’s brilliant researchers decided to base their industry- and world-changing conclusions on what companies voluntarily confess at conferences.
Hahahaha. . .
That’s like surveying gym-goers in January and concluding that 95% of humanity fails at fitness. Genius, you guys. What does NANDA actually stand for anyway?
- Narrative About Nothing, Dressed Academically,
- Now Announcing Nonsense, Disguised as Analysis.
- Nice Acronym, No Data Anyway?
Post your answer in the comments. The winner get’s a copy of the charred remains of “The State of AI In Business 2025” signed by me.

‡ As in “high on . . . “
Sample size and statistical analysis
Let’s continue filleting this two months ol’ fish scientifically, now, shall we?
I star with the statistical elephant in the room.
MIT’s “groundbreaking” State of AI report stands on a foundation that is so small, it could double as a rounding error.

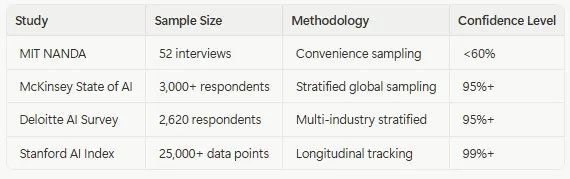
MIT’s study relies on:
- 52 qualitative interviews (that’s roughly 0.0001% of global enterprises, or about the same odds as winning a free upgrade on Ryanair)
- 153 conference survey responses (also known as “people who had nothing better to do between keynote sessions”)
- 300 “public AI initiatives” (a.k.a. press releases and LinkedIn / GitHub ‘vanity’ projects)
Now, if you do the math, which, clearly, FANDA† didn’t, the statistical power here is laughable.
So, let’s do it for them. . .
Statistical Power Calculation: For a population of 500,000+ global enterprises, achieving 95% confidence with a ±3% margin of error would require roughly 1,067 respondents.
MIT’s effective sample of 52 interviews provides:
- Confidence Level: <60%
- Margin of Error: ±13.7%
- Statistical Power: Insufficient for generalization, unless you’re trying to generalize to your own research group‡.
In plain language, they tried to map the global AI landscape using a magnifying glass and a handful of gossip.

† FANDA, Federation for Artificial Nonsense and Dubious Academics – ‡ The study’s sample is so small and so biased that the only thing you can confidently conclude is how people inside the same circle of researchers think. Not how the entire world thinks.
The ROI time trap
Sit back, relax, and think about Hans Zimmer’s main theme from Interstellar, and if you have no idea what I’m talking about, well then, shame on you. Go watch it, cry a little about the meaning of time, and then try retaking that relativity exam you flunked in your first year!
TIME. That inconvenient, linear dimension that MIT has conveniently decided to ignore in their “ground-breaking” paper (I’d rather say “credibility shattering”). According to the State of AI in Business 2025 report, success or failure hinges on whether an enterprise AI project can cough up measurable ROI within six months.
My dude!
Six. Months. For enterprise-scale AI!
Mon dieu!
That is not research man, that is bi-quarterly capitalism in a lab coat. It is obvious that nonnadem have never done a real day’s work outside their fluorescent-lit labs where they confuse lab simulations with reality and wonder why nothing ever scales outside their own petri dish.

Now, let’s put that into perspective.
If MIT had applied the same yardstick to every other major technological revolution, they would’ve declared the internet, cloud computing, and mobile all catastrophic failures, right up until the exact moment those “failures” started shaping civilization.
Look and pretend to be amazed by my simple explanation:
Historical technology maturation timelines
- Internet (Commercial): 1995 → 2005 (10 years to mainstream ROI)
- Cloud Computing (AWS): 2006 → 2015 (9 years to profitability)
- Mobile Computing: 2007 → 2017 (10 years to enterprise transformation)
- Enterprise Software: 18–36 months (average to measurable ROI)
So, if we take MIT’s logic and apply it to every piece of disruptive tech we witnessed over the last thirty years, then every technological breakthrough in history was a fiscal disaster for at least a decade, until it . . . wasn’t.
That is the same as declaring your kid a freaking failure because he hasn’t filed his first tax return by age six.
Get it?
Let’s look specifically at AI, which, unlike traditional IT, doesn’t really install . . . it adapts. It has to crawl through data maturity, human resistance, regulatory molasses (EU as always), and the fear of middle management before anyone dares to call it “it’s, um, uh, o-o-operational”.
Empirical AI implementation timelines. Of course, I’ve had my fair share of running enterprise AI projects, but let’s not get trapped in my own little sandbox of experience, lest we tumble into the same echo chamber MIT did, because that is exactly how MIT ended up mistaking a puddle for an ocean.
- Pilot to Production: 12–18 months (CloudFactory, 2025)
- Measurable Business Impact: 18–36 months (Enterprise Technology Adoption Study, 2025)
- Full Organizational Integration: 3–5 years (McKinsey Digital Transformation Research)
That’s not failure, people. That is more close to being physics. But according to MIT’s stopwatch methodology, if your model doesn’t print money by Q2, it is time to pack it up and go back to Excel.
Now let’s do a relative ‘Gedankenexperiment”, and that’s where it gets spicy. I call it, “The Bozo the Benevolent† reality check™®©”.
If you do a little diggin’ you learn that Amazon Web Services launched in 2006, and operated at a loss for nine years, and only turned profitable in 2015.
Today it is a $70-billion-a-year money printer with profit margins around 30%.
KA-CHING!
By MIT’s six-month ROI communist doctrine, AWS would’ve been labeled a catastrophic failure for nearly a decade. Jeff Bezos famously said, “All overnight success takes about 10 years,” but MIT’s researchers missed that memo of a 21st century business mogul who is the second richest man on earth because of his business prowess, cause they were too busy looking into their petri dish and extrapolating business with their early 20th century ruler.
The irony is so thick you could cut it with a blockchain, and then tokenize it for grant funding.
In the end, MIT did NOT build a temporal evaluation framework. They built a panic button for impatient investors. 21st century exponential technology does not match outdated “Scientific rigor” practises. You can’t benchmark exponential progress with the same tools you used to weigh fruit flies in 1973. Yet here we are, and they are calling it “scientific rigor”. But this sounds more like rigor mortis because it laughs at them, and it will automate them out of existence.
And good riddens.
† Jeff Bezos. How many times do I have to explain this to you?!?

Success, according to people who’ve never succeeded in business
MIT’s definition of “success” was written by someone who has never actually deployed anything more complex than a spreadsheet macro. According to the State of AI in Business 2025 report, an AI project only counts as successful if it:
- Reaches deployment beyond pilot phase with measurable KPIs, and
- Delivers ROI within six months post-pilot.
Sigh.
That is not a measurement framework, people, that’s a ruler wearing an academic mason hat. By defining “success” in terms of speed and profit, MIT effectively erased the entire value spectrum that makes enterprise AI transformative in the first place.
The academic consensus on AI value measurement goes far beyond financial ROI:
- Operational efficiency gains are often invisible in the first year but exponential thereafter. (Not captured by MIT.)
- Quality improvement metrics mean better accuracy, decisioning, and customer outcomes. (Ignored entirely.)
- Employee productivity enhancement which positions AI as augmentation, not replacement. (Excluded from analysis.)
- Risk reduction and compliance benefits. These are huge strategic wins that rarely appear on quarterly sheets. (Not measured.)
- Strategic capability development is the long-term compounding edge that actually defines digital transformation. (Completely outside their six-month worldview.)
What MIT calls “rigor” is really just ROI reductionism. It is an obsession with short-term profitability that is posing as scientific objectivity. Man, it as if they tried to measure evolution by quarterly stock performance.
Duh . . .
You don’t measure paradigm shifts with a stopwatch.
You measure them by the compounding effects they unleash, like efficiency, resilience, capability, and scale, but instead of acknowledging that, the freshmen at MIT built a framework that rewards immediacy and punishes patience, and that my smart ass-friends, is the intellectual equivalent of grading a seed for not being a tree after 180 days.
So when the report concludes that “95% of enterprise AI projects fail”, what it’s really saying is
“95% of AI projects don’t deliver instant gratification to people who don’t understand time”.
And that, my friends, is proof this report is the result of impatient MIT researchers of the TikTok generation, who are desperate to score the next dopamine hit of publicity, so they keep chasing headlines instead of horizons. I call it academic ADHD fast-food because it is pre-packaged, overhyped, and engineered for virality rather than validity.
They didn’t study failure.
They commodified it, because in the attention economy, even disappointment can be monetized, as long as it trends before lunch.

MIT also picked the wrong crowd
MIT’s sampling strategy makes it painfully obvious that the authors have spent more time in conference halls than in production environments. Their data collection relied on people who volunteered to talk about AI, and that, my friends, is as representative as asking patients in a waiting room how well healthcare is doing.
MIT’s “survey methodology” was built around AI conference attendees, which is a group that almost guarantees systematic bias.
- Self-selection bias. Companies with problems are more likely to show up at AI events, hoping to find solutions or partners.
- Survivorship bias. The truly failed projects don’t make it to the podium — or the slides. They’re quietly buried in internal post-mortems.
- Temporal bias. Conferences naturally attract early adopters and experimenters, not the broader population of mature, quietly successful implementers.
In short, MIT built its dataset inside an echo chamber, a self-reinforcing loop of enthusiasm, failure, and performative optimism.
The publicity trap
Then there’s the even bigger bias. MIT’s fixation on so-called “public AI initiatives”.
Hold onto your hats for this one, cause it’s gonna storm. . .
At first glance, this sounds rather legitimate, until it is not, because then you realize “public” often means “PR stunt”.
Oooh, now I get it!
- PR vs. Strategy. Public announcements or reports are usually marketing exercises, not indicators of strategic transformation.
- Concealed success. Real competitive advantage rarely comes with a press release. The companies actually winning with AI don’t advertise the playbook.
- Sample skew. Public initiatives tend to be pilots, demos, and “innovation theater”, and not production-grade systems that move revenue.
So in the end, M.I.T†. didn’t study AI in business, they studied AI in brochures. Their “sample” represents the loudest voices in the room, not the most competent.
Hahahaha.
Just think about it.
It’s like evaluating marriage success by interviewing people at divorce hearings!
And from that bias-filled dataset, they had the audacity to generalize to the global enterprise landscape. That’s not science. That is empiricism which is usually confined to LinkedIn. It looks more like networking than it does look like research.
† MIT apparently stands for “Marketing In Tweed” cause it is academia’s oldest MLM. It comes with citations, self-importance and above all – PowerPoint prophecy.
Contradictory empirical evidence
MIT’s lil’ bubble deflating report distorts reality, and it buries it under six months of spreadsheet they call science. The moment you line up their claims against large-scale empirical studies, the whole thing collapses like a sysadmin who just got the electricity bill after installing an LLM. According to NANDA PROPAGANDA, only 5% of enterprise AI projects succeed. And that is a number which is so depressingly specific that it must have been handpicked to trigger headlines.
But here’s what happens when you compare their “findings” with, like, real data:
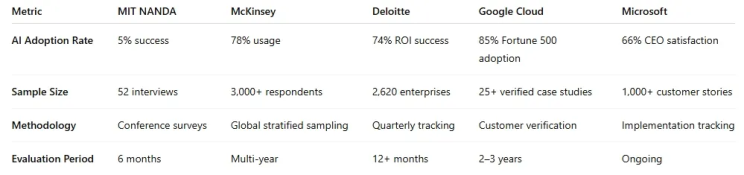
When you see that side by side, it is not research. Pfff. . . it’s more like a self-parody. MIT built its argument on hallway surveys and conference anecdotes, while everyone else spent years tracking real implementations across sectors, continents, and fiscal cycles. Their six-month ROI window alone disqualifies the entire study from serious comparison.
And then comes the punchline, MIT gave the energy sector a flat “zero” success score, which is impressive, considering companies like AES Corporation cut audit costs by 99% (from 14 days to one hour), Shell saved over $200 million through AI-driven exploration optimization, and BP reduced drilling time by 30% using predictive geological models.
And financial services tell the same story, JPMorgan Chase saves $150 million a year via AI fraud detection, Goldman Sachs cut trade settlement times by 40%, and Mastercard boosted real-time fraud accuracy by 85%.
These are production systems, people, and NOT demo projects. So unless every major consultancy and Fortune 500 firm collectively hallucinated their ROI, MIT NANDA PROPAGANDA’s six-month, 52-interview “study” was measuring nothing more than echo.
The data contradicts MIT’s conclusion. Oh, let me rephrase it slightly different.
caps-lock—ON
IT OBLITERATES IT.
caps-lock—OFF
Their so-called State of AI report isn’t an assessment of the industry. It is an academic hallucination even ChatGPT could be proud of. And it is full of prestige and it is marketed as insight.
Ever felt that too-much–umami-tasting–chemicals nausea after you’ve eaten your fill at a McDonald’s? Yeah. Me too. And that’s exactly what I felt after reading the report.
And this is precisely why I didn’t write about it before.
Geographic and cultural bias assessment
Ok, truth be told, this one feels like I’m whining, but if you set out to filet a stinking fish, you gotsta do it right, else the stench will remain forever. MIT’s State of AI in Business 2025 suffers from the same geographical myopia that infects most Western “global” research which is the assumption that the world starts and ends somewhere around . . . Silicon Valley.
Yeah. So small you’d nearly miss it.
The Stanford AI Index (2025) in contrast, tells a wildly different story, and it is showing enormous variation in AI optimism and adoption rates by region. China (83%), Indonesia (80%), and Thailand (77%) report overwhelmingly positive outlooks, compared to a more cautious 56% in the United States and 62% across Europe.
MIT’s US-centric sampling completely ignores this geographical diversity, and is flattening a complex global landscape that multinationals operate in, into a single, self-referential narrative. In other words, they studied America and called it Earth.
That’s just laziness.
Add to that the cultural factors shaping how organizations report AI success, and the bias grows louder than the ball bearings in my Land Rover Discovery. Asian markets tend to disclose positive outcomes more freely, because their culture is driven by collective achievement and national policy incentives, and European markets, are shaped by transparency regulations like the EU AI Act, which mandate detailed reporting on AI impact and compliance.
And the US markets?
Yup. Competitive secrecy reigns supreme. Successful implementations are guarded like the GPS coordinates of a leprechaun’s gold stash, and MIT’s methodology, by sampling primarily from this closed-mouth ecosystem, systematically under-represents the regions most vocal about successful AI adoption.
It’s not that global AI success doesn’t exist, it is that MIT didn’t bother to look where it was happening. So when they claim “95% of enterprise AI projects fail”, but what they really mean is “95% of the people we asked on a conference in our own backyard weren’t bragging about success”.
Institutional bias and conflict of interest
If the data didn’t already make you suspicious, the commercial fingerprints all over the State of AI in Business 2025 report should. The so-called NANDA Project wasn’t a neutral research endeavor, because it was a sales pitch with citations.
Cause I started digging into the background of the peeps behind the reseach.
The report is waving the MIT flag, but the team was simultaneously developing MCP/A2A protocols.
Dawudnow?
Hello-hoooo – these are just about the two protocols that are actually a game-changer. MCP or Model.. well, yeah, just look it up yourself if you’re a noob, and A2A (agent-to-agent-protocol) are all about making (agentic) AI connect to all kinds of systems and other agents.
So they’re definitely not dumb.
But, the very same agentic AI frameworks their “study” conveniently concludes are the future of enterprise success.
I’ll wait for the dust to settle in your brain. . .
Jeez Louise.
THIS IS A TRUE BOMBSHELL†
It’s like you’re Proctologist & Gamble and you’re running a toothpaste study while owning Colgate.
Every layer of the report just shouts commercial motivation! It is a product in search of validation, a narrative dressed up as research. Add to that a total lack of transparency about funding sources and commercial affiliations, and it becomes clear this wasn’t peer-reviewed science, but pre-approved marketing.

The red flags for academic independence practically glow in the dark.
The conclusions align a little too perfectly with NANDA’s own commercial offerings and that is suggesting that the outcome was predetermined long before the first survey hit a conference inbox.
Contradictory data sources were either ignored or surgically removed, replaced with anecdotes that flatter their agenda. The methodology opacity alone is enough to make a statistician want to quit his job → insufficient detail for replication, missing sample validation, and no published review process. And then there’s the speed. This thing was literally rushed to publication, and it was bypassing every safeguard that’s supposed to separate academia from advertising.
So when NANDA declares that only 5% of AI projects succeed and that “Agentic AI” is the salvation, don’t mistake that for insight. It’s not a revelation, lemme spell it out for you IT IS REVENUEUE OPTIMIZATION.
What you have been reading isn’t research at all. It is a conflict-of-interest case study in real time, and to me it is proof that even world-class institutions will trade rigor for relevance if it gets them another round of funding and a headline on TechCrunch.
And that is why I am an independent researcher. Nobody is breathing down my neck to publish just one more popular story for the presses, to feed the fund-raising machine. I pay for my own time. And maybe that’s what every researcher should do who is producing statements that impact businesses. I like the spotlight, and be on the edge of science with my work. Yes. But I am transparent about it.
Think of it what you will, but at least I’m not selling my work to the highest bidder.
† Marc Drees remind me to drop the link with proof in the comments, please.
Adding insult to injury
Here’s where the math finally buries the myth. MIT’s State of AI in Business 2025 implodes under statistical malpractice. With only 52 interviews, their 95% confidence interval for a 95% failure rate stretches from 82.3% to 99.7%, with a margin of error of ±8.7% and statistical power of 0.23 and that is roughly as reliable as flipping a coin in a thunderstorm.
Every major technology follows the same predictable S-curve → experimentation (2018–2022), scaling (2023–2025), adoption (2026–2030), and maturity (2031+). MIT chose to measure AI right in the middle of its awkward teenage years → the scaling phase, where costs are high, and returns are slow. In this phase, every system is still tripping over its own learning curve.
You realize MIT is measuring . . . noise.
Yup. Noise.
Even if the math held up, their timing kills it.
MIT measured the chaos of scaling and called it failure. The past (yes, there was a past pre-ChatGPT) taught us that AI value isn’t linear but compound. Year 1 investment, Year 2 optimization, Year 3+ exponential returns. MIT’s six-month window caught only the cost, never the compounding gain.
They studied the down payment and ignored the house.
If this were a PhD thesis, it’d be a case study in haste, hubris, and headline addiction. A valid study needs 1,000+ enterprises, 24 months, and both quantitative and qualitative data. But MIT delivered a statistical Happy Meal. It is quick, greasy, and just engineered for clicks and their advertisers. The real state of AI is an ecosystem mid-growth, still finding its balance. So, MIT didn’t measure collapse, but they measured impatience instead.
So here’s the summary. If this came from Proctologist & Gamble Research Co., I’d applaud the consistency. But from MIT, it is an embarrassment buried under a large chunk of statistical diarrhea.
Final Recommendation, Next time, use a sample size larger than your contact list, and a timeline longer than your (or your advertiser’s) attention span.
This brings me to the last paragraph – and then it’s over, I promise you . . .
The peer review that never was
You’d think a report carrying the MIT brand would’ve gone through some kind of holy trinity of peer review†. You know, the kind that makes your head spin a full 360 degrees while your so-called academic “friends” projectile-vomit their insult to your IQ across the seminar room. But instead of exorcising the bad ideas, they baptized them in footnotes and called it science.
The only trinity this report ever met was Prestige, Publicity, and Paycheck, and not a single one of them believes in truth, but what we got instead was a beautifully typeset marketing deck posing as an academic drag-queen. Peer review is supposed to be the firewall against this kind of thing, the intellectual immune system that catches sloppy sampling, lazy methodology, and speculative conclusions before they infect public discourse, but the guys behind MIT’s State of AI in Business 2025 seems to have slipped through the cracks. If this paper were submitted to a proper journal, reviewers would’ve lit it on fire in the first paragraph:
Inadequate sample size, flawed time horizon, biased sources, and such shallow metrics they would evaporate if they had ever seen daylight.
But when your reviewers are your colleagues, your funders, or your LinkedIn followers, the line between validation and vanity blurs fast.
What happened here isn’t peer review. It is peer reassurance. A polite round of mutual head-nodding in the echo chamber of institutional prestige, and the result is a document that looks rigorous enough to fool a policymaker, polished enough to impress a boardroom, and shallow enough to trend on social media.
It is Academic Workslop. Read: Workslop is the new office plague | LinkedIn
And let’s be honest, MIT isn’t alone in this. Academia at large has turned “peer review” into a ritual that signals integrity while quietly trading it for visibility, because when your funding, your reputation, AND your next job depend on how often you are cited, not how right you are, the incentives are clear.
So, this report is NOT an outlier. It is, however, a symptom.
A sign that the institutions we once trusted to filter truth from noise are now optimizing for engagement over enlightenment. And if that doesn’t make you question every headline that begins with “According to MIT…”, it should.
Because when prestige becomes the metric, truth becomes optional.
† Ah, the holy trinity of peer review. In theory, it’s supposed to be the sacred process that keeps academic nonsense from leaking into daylight. In practice, it’s more like a group session for egos with a fetish for citations. The real “holy trinity” of peer review is validity, originality, and significance. In other words, whether the methods make sense, the ideas are new, and the work actually matters instead of just rearranging the PowerPoints.
The credibility collapse
Professor Kevin Werbach from Wharton read the MIT report multiple times and still can’t understand where the 95% claim comes from. He demands MIT either release the supporting data or retract the report.
When a Wharton professor can’t find the methodology behind your headline statistic , you’ve got a credibility problem bigger than Theranos.
So the conclusion after statistically and logically filleting MIT’s report is that the 95% failure rate is a sensational lie designed to sell NANDA’s agentic AI protocols.

The methodology is garbage, the sample is biased, the timeline is unrealistic, and the conclusions contradict overwhelming evidence from more credible sources. So who’s with me for renaming MIT’s report to “the credibility of MIT in business 2025” and filed under “Marketing Materials“, not “Academic Research”.
Institutional bias and commercial motivation just corrupt the scientific process. The only divide here is between those doing the work and those selling slogans.
I build AI by day and warn about it by night. Even when it’s about Academia.
Signing off,
Marco
I build AI by day and warn about it by night. I call it job security. Big Tech keeps inflating its promises, and I just bring the pins and clean up the mess.
👉 Think a friend would enjoy this too? Share the newsletter and let them join the conversation. LinkedIn, Google and the AI engines appreciates your likes by making my articles available to more readers.
To keep you doomscrolling 👇
- I may have found a solution to Vibe Coding’s technical debt problem | LinkedIn
- Shadow AI isn’t rebellion it’s office survival | LinkedIn
- Macrohard is Musk’s middle finger to Microsoft | LinkedIn
- We are in the midst of an incremental apocalypse and only the 1% are prepared | LinkedIn
- Did ChatGPT actually steal your job? (Including job risk-assessment tool) | LinkedIn
- Living in the post-human economy | LinkedIn
- Vibe Coding is gonna spawn the most braindead software generation ever | LinkedIn
- Workslop is the new office plague | LinkedIn
- The funniest comments ever left in source code | LinkedIn
- The Sloppiverse is here, and what are the consequences for writing and speaking? | LinkedIn
- OpenAI finally confesses their bots are chronic liars | LinkedIn
- Money, the final frontier. . . | LinkedIn
- Kickstarter exposed. The ultimate honeytrap for investors | LinkedIn
- China’s AI+ plan and the Manus middle finger | LinkedIn
- Autopsy of an algorithm – Is building an audience still worth it these days? | LinkedIn
- AI is screwing with your résumé and you’re letting it happen | LinkedIn
- Oops! I did it again. . . | LinkedIn
- Palantir turns your life into a spreadsheet | LinkedIn
- Another nail in the coffin – AI’s not ‘reasoning’ at all | LinkedIn
- How AI went from miracle to bubble. An interactive timeline | LinkedIn
- The day vibe coding jobs got real and half the dev world cried into their keyboards | LinkedIn
- The Buy Now – Cry Later company learns about karma | LinkedIn


Leave a comment