I wanted a calm Sunday. Inbox, coffee, vague hope. Then I made the mistake of reading OpenAI’s latest “research breakthrough”. No, it’s not a cure for hallucinations, it is a belated admission that their multi-billion-dollar bots have been bullshitting on generative autopilot for three years straight.
But they finally said the quiet part out loud – that language models hallucinate not because the data is bad, not because transformers operate like a casino, but because the entire training system rewards them for guessing instead of shutting up.
Read: “Why Language Models Hallucinate” (here’s the blog post).
🫨 WHAT ?! 🫢
Their biggest statement in their conclusions was that it’s more about the training setup, and not so much the inherent probabilistic nature of the model?
Wow, now that is wild.
Because most of the field has been saying the opposite for years. I think I can cite at least three papers that talk about statistics being the culprit.
The “probabilistic nature” part is simple, a transformer doesn’t know truth, it knows odds. Every time it generates text, it rolls weighted dice across a vocabulary of 50,000 tokens and picks the likeliest next word. The system is literally designed to keep producing output, even when the dice don’t favor the truth. If the training data doesn’t cover the fact, or if it’s too rare, the probabilities collapse into mush, and the model just guesses something plausible.
So for OpenAI to pivot and say hallucinations are not so much about the dice and more about the way we grade the answers is a big reframing.
The thing here is that they’re not denying that probability makes the mess inevitable, but they’re saying the mess is magnified because benchmarks and training procedures actively prefer a confident wrong answer over an honest “I don’t know”.
More rants after the commercial brake:
- Download this free eBook from Russell Thomas about rituals to resist the noise generated by the attention economy to regain clarity.
- Comment on my recent research, love to know your opinion 🤔
- Connect with me on Linkedin 🙏
- Subscribe to TechTonic Shifts to get your daily dose of tech 📰
Let’s strip it down
A language model is trained in two big phases. First is pre-training. That’s where it eats an obscene amount of text and learns to predict the next word in a sequence. “
“The cat sat on the ___”.
Easy.
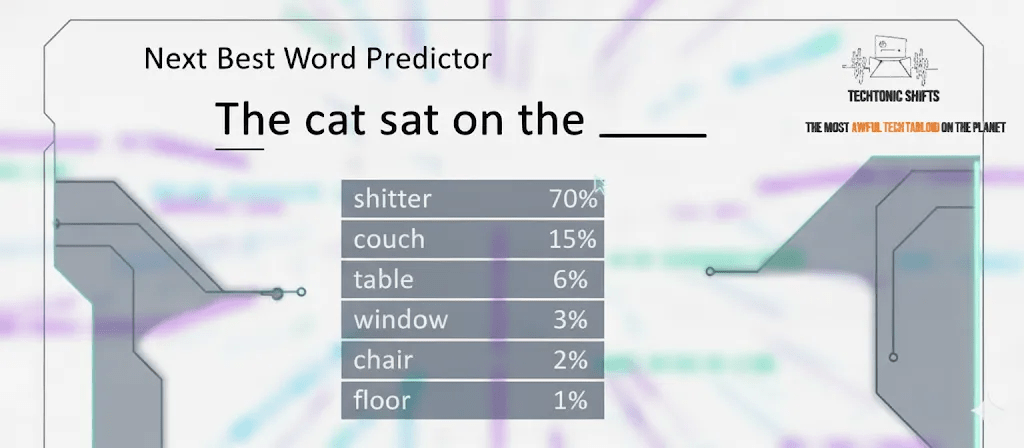
But even if it hasn’t actually learned the right pattern, it is still forced to make a guess.
Never silence. Always output.
The second is post-training. This is where researchers fine-tune it using benchmarks and feedback, telling it “good bot” when it lands on the right answer.

But there’s poison in the well, because the benchmarks only count accuracy, and not honesty, so if the model says “I don’t know”, it gets penalized. If it fabricates something crap with swagger and happens to luck into a right answer, then it gets rewarded.
Have you raised a child? Yes, I mean you! Have you ever paid them every time they lie to you in your face, with confidence? Yeah, that’s how it’s organized now and why them peeps at OpenAI thought there was something wrong with the training as well.
So hallucinations aren’t just random noise.
They are trained behavior. Models learned that guessing wrong is still better for their grades than refusing to guess.
And OpenAI’s researchers spell it out with an exclamation mark in their blog post “language models hallucinate because training and evaluation procedures reward guessing over acknowledging uncertainty”.
Well now, them bots don’t know what “uncertainty” is, they’re built to complete the sequence and not to reason about whether the sequence is a crock of horseshit. You have different ways you can handle that, but they all involve other systems. It’s not internal to the model.
The paper even shows a delightful paradox.
GPT-5 abstains sometimes, saying “I don’t know” and for that humble ‘character trait’ it gets slammed in benchmark scores. And GPT-4 plays the game along and is spewing answers right or wrong and ends up with a higher “accuracy” rate.
Awww. So unfair.
In other words, the system rewards compulsive lying over cautious truth-telling.

What is even worse, is that the industry has doubled down on this nonsense. Leaderboards [those public rankings where labs show off their models], they don’t allow for nuance.
Right or wrong, no middle ground.
And companies chase those leaderboard points, and that means nobody wants to admit their models should sometimes just say, “Nah, I got nothing”.
It is just guessing patterns
Now, let me explain a side-problem that this paper only whispers about which is out-of-distribution data. That’s what you get when a model sees a novel problem that it wasn’t trained on.
We hoomans struggle but we can of course try to improvise.
But the machines can’t.
They just collapse.
They start making up deranged answers because their entire wiring tells them to always produce something. That is hallucination in its purest form. And the real world is 99% OOD.

See the magnitude of the problem at hand here?
Your workflow, your messy documents, your dumb edge cases, they are all outside of the neat bubble of training data. So every time a chatbot acts confident on something it has never seen, you’re just watching OOD failure and the bot presents it as wisdom.
And it even gets nastier.
Even if you fix the benchmark issue by punishing wrong answers and rewarding abstaining, you cannot fix OOD because the model still doesn’t know when it doesn’t know. It doesn’t have intuition, it can’t play improv theater or what nerds call “generalization”.
It-is-just-guessing-patterns.
That means the hallucination problem is not only about bad the incentives we give the bot during training, it is about the limits of the whole architecture. Transformers remain parrots with calculators, and not reasoners with brains.
But OpenAI doesn’t want you to think about that. They would rather you believe that adding penalties to benchmarks will be enough.
They still hinge on the thought that if you make the bot afraid of being wrong, it maybe will learn to admit ignorance like an adult instead of lying. They even suggest that embedding this penalty system into the major benchmarks like SWE-bench or GPQA, so models get dinged for wrong answers rather than for abstaining.
Nice idea.
But that only solves half the mess. The minute a model faces OOD, it’s back to improvisational theater.
And we all know that those companies have zero incentive to adopt benchmarks that make their products look worse, because leaderboards are marketing, and not science. Telling a CEO that their chatbot admits ignorance 40% of the time isn’t a great sales pitch.
So the hallucination plague will continue, just with a fresh coat of “research progress” -paint on top.
What will happen next. . .
I can see the headlines already. Consultants will invent new buzzwords like “confidence calibration”, and vendors will brag that their model is “less of a liar than last year”. Of course OpenAI will trumpet “transparency” and still pray that nobody notices the OOD landmines. And we will keep on getting confidently wrong answers, but it will be wrapped in perfect grammar, and with ChatGPT-5 it will be delivered bloody fast.
So, hallucinations are the rotten core of the system, and now it’s not only the model, but also about the way we train it and how we organize the data.
These hallucinations exist because we taught machines to value fluent output over factual accuracy.
Because silence doesn’t score points.
Because Big Tech raced for ceiling heights while leaving the floor riddled with trapdoors.
And until they rebuild the whole freaking evaluation system and confront OOD, the bots will keep lying more than they already do.
I’ll put it plainly. Hallucinations are the last wall between generative AI as a toy and generative AI as actual technology making things efficient, but right now, the ceiling’s painted gold, but the floor is sawdust. And every time you walk on it, you fall through.
Signing off,
Marco
I build AI by day and warn about it by night. I call it job security. Big Tech keeps inflating its promises, and I just bring the pins (and the solutions).
Think a friend would enjoy this too? Share the newsletter and let them join the conversation. LinkedIn, Google and the AI engines appreciates your likes by making my articles available to more readers.
To keep you doomscrolling 👇
- The chicken that refused to die | LinkedIn
- Vibe Coding is gonna spawn the most braindead software generation ever | LinkedIn
- The funniest comments ever left in source code | LinkedIn
- Today’s tech circus is a 1920s Wall Street reboot | LinkedIn
- The Sloppiverse is here, and what are the consequences for writing and speaking? | LinkedIn
- Why we’re all writing like shit on purpose now | LinkedIn
- Creating a hero’s journey for your AI-strategy | LinkedIn
- How corporations fell in love with AI, woke up with ashes, and called It ‘innovation’ | LinkedIn
- The corporate body snatchers | LinkedIn
- Screw your AI witch hunt, you illiterate gits | LinkedIn
- AI perverts make millions undressing your daughters for fun and profit | LinkedIn
- The state of tech-jobs 2025 | LinkedIn
- Meet the sloppers who can’t function without asking AI everything | LinkedIn


Leave a comment